Jun 25, 2025
·
SHare:

AI is now better at writing code than 98% of programmers, but it's not better than YOU! If you are here reading this, you are part of the 2% - Congrats! ;) Jokes aside, a recent survey of YCombinator showed that new waves of startups generate 95% of code through AI tools, and Anthropic's CEO, Dario Amodei said that AI will most likely generate 90% of all code in the future. In order to remain a competitive developer it's important to understand how Large Language Models work and how they generate human-like text, sophisticated code, and answer complex questions. You need more than just prompting skills. You need to understand what’s behind the curtain: how these models work and how they reason.
Let’s get straight to the point. Most of today's LLMs that you've been using are based on an underlying architecture: The Transformer. Understanding the Transformer is key to grasping how these models learn, process, and generate language.
This blog post is a good starting point to learn about the following concepts: Self-attention, Decoder, Encoder, and understand the general impact of Transformer architecture on LLMs. Get ready to dive in.
So, what is Transformer architecture?
Introduced by Google in the 2017 paper "Attention Is All You Need," the Transformer architecture fundamentally changed how sequence-to-sequence tasks are approached. Before transformers, recurrent neural networks (RNNs) and convolutional neural networks (CNNs) were dominant, but they struggled with long-range dependencies in text and were difficult to parallelize effectively during training. The Transformer addressed these limitations by introducing a mechanism called self-attention.
Here is a simplified example to explain the implication of self-attention and how it differs from RNNs and CNNs. Let’s analyze the following sentence:
“The concert, which had been scheduled for months and eagerly anticipated by thousands of fans, was canceled because of the weather.”
RNNs process text word by word, so in a sentence like the above, it struggles to connect the word “was” with the subject “concert” because of the long and distracting phrase in between, which leads to confusion and poor understanding. CNNs would analyze small chunks of text (e.g., 3–5 words), but still can’t connect far-apart words like “concert” and “was canceled” without stacking many layers, which becomes inefficient. Transformers solve this with self-attention: “was” can directly see “concert”, no matter how far apart, making understanding long sentences much more accurate and efficient.
Moreover, imagine you're reading a book and trying to understand a character’s actions in chapter 10. To do that, you might need to remember something from chapter 2.
RNNs read the book one page at a time, in order. To understand chapter 10, they would have to carry memory from chapter 2 through chapters 3, 4, 5, and so on. This makes it hard to remember important things from early on.
Transformers, on the other hand, can look at the whole book at once. They can jump straight from chapter 10 back to chapter 2 and see the connection instantly. This is possible because of self-attention.
Now let's dive deeper into the concept of self-attention. Self-attention allows the model to weigh the importance of different parts of the input sequence relative to each other, regardless of their distance. This breakthrough enabled more efficient training on massive datasets and better capture of long-range dependencies, paving the way for the powerful LLMs we see today.
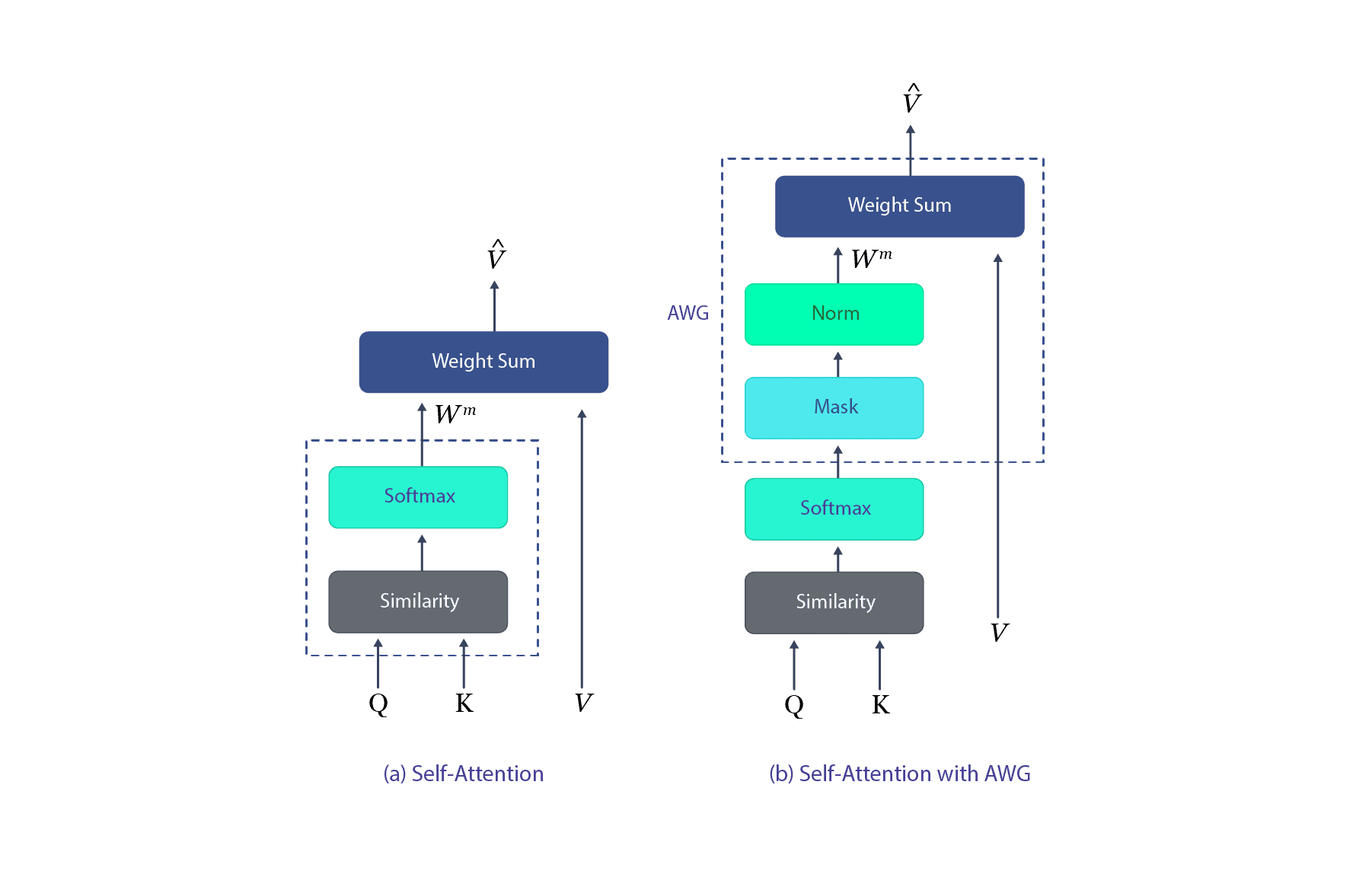
Weitao, Jiang & Li, Xiying & Hu, Haifeng & Lu, Qiang & Liu, Bohong. (2021). Multi-Gate Attention Network for Image Captioning. IEEE Access. PP. 1-1. 10.1109/ACCESS.2021.3067607.
The above diagram illustrates how a neural network computes attention weights to focus on different parts of the input. The process begins with the input vectors: Q (Query), K (Key), and V (Value). First, the Query and Key are compared in the Similarity block, which calculates how relevant each element of the input is to the others. This generates a set of scores that reflect the importance of each word in context. These scores are passed to the Softmax block, which converts them into a probability distribution, essentially assigning attention weights (W) to each input token. These weights are then used to compute a weighted sum of the Value vectors, highlighting the most relevant parts of the sequence. The result is a new vector representation (V̂) that incorporates contextual information, enabling the model to "attend" to the most important words dynamically.
At its core, a standard Transformer consists of two main components that work in tandem: an Encoder and a Decoder. Some LLMs might use only the Encoder (like BERT), others only the Decoder (like GPT models), and some use both (like T5).
💡 What is a token?
In natural language processing (NLP), a token is a unit of text used as input to a model. It can be a word, a part of a word, or even a character, depending on the tokenization method. For example, the sentence "Transformers are powerful" might be split into tokens like ["Transform", "##ers", "are", "powerful"] using subword tokenization. These tokens are then converted into vectors and fed into the neural network.
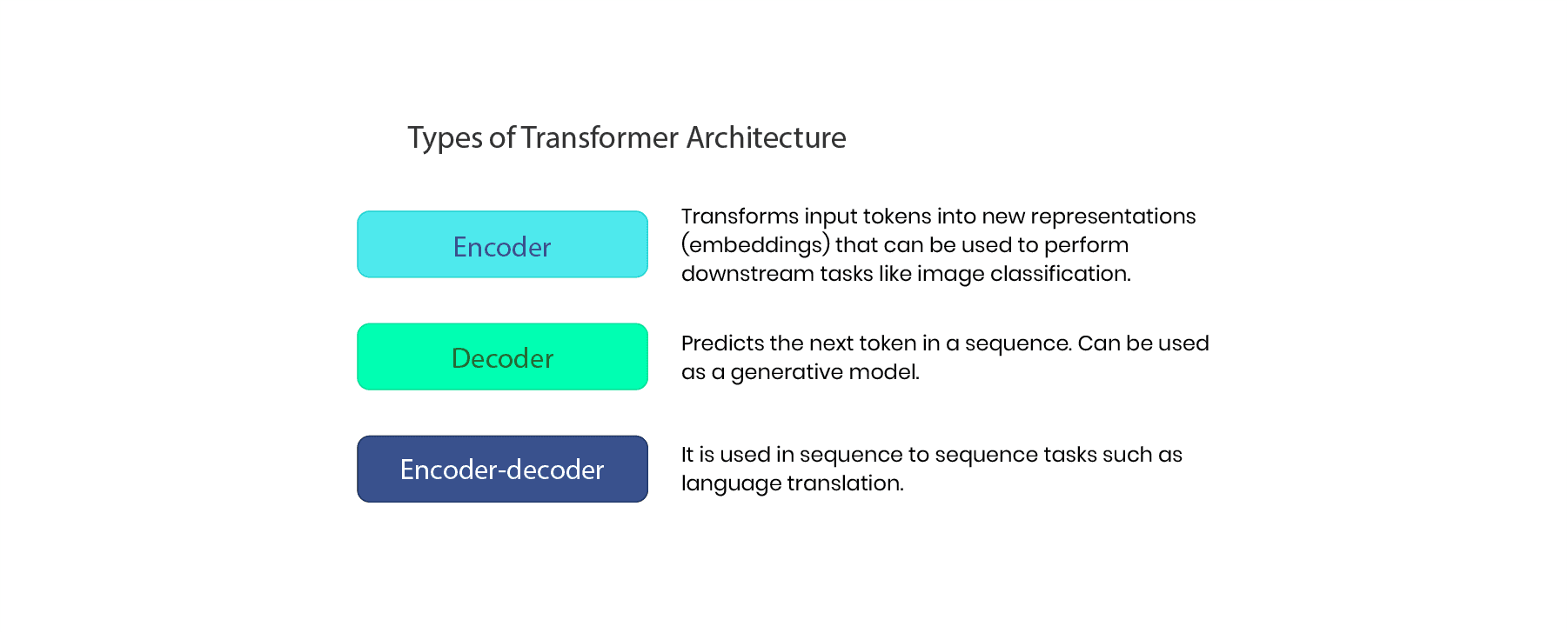
Let's break down each of these crucial components.
The Encoder: Understanding the Input
The Encoder's primary role is to process the input sequence and transform it into a rich, contextual representation, often referred to as "embeddings." Think of the Encoder as the "reader" of the Transformer. It takes raw text, tokenizes it into numerical representations, and then processes these tokens to understand their meaning in the context of the entire input.
The Encoder is typically composed of a stack of identical layers. Each layer contains two main sub-layers: Multi-Head Self-Attention Mechanism (as mentioned above) and Feed-Forward Network.
Multi-Head Self-Attention Mechanism: This is where the magic happens. The self-attention mechanism allows the model to look at other words in the input sequence as it encodes each word. For example, if the input sentence is "The animal didn't cross the street because it was too tired," when processing the word "it," the self-attention mechanism helps the model determine that "it" refers to "the animal" and not "the street." It learns to assign different "attention weights" to other words in the sentence, indicating their relevance to the current word being processed.
The self-attention mechanism works by creating three vectors for each token: a Query (Q), a Key (K), and a Value (V).
The Query vector represents the word we are currently focusing on.
The Key vectors represent all the words in the sequence.
The Value vectors contain the actual information of the words.
To determine how much attention each word should pay to others, the Query of the current word is multiplied by the Keys of all other words. This generates "scores" that indicate the similarity or relevance. These scores are then scaled and passed through a softmax function to get attention weights, ensuring they sum to 1. Finally, these weights are multiplied by the Value vectors and summed up, resulting in a new representation for the word that incorporates contextual information from the entire sequence.
The "Multi-Head" aspect means that the self-attention mechanism is run multiple times in parallel, each with different learned linear transformations (different sets of Q, K, V matrices). The concatenated outputs (Concat) from these multiple heads are then linearly transformed, yielding a more comprehensive and robust contextual understanding.
Feed-Forward Network: After the self-attention sub-layer, the output for each position in the sequence passes through a simple, position-wise fully connected (FC) feed-forward network. This network is applied independently to each position and serves to further process the information derived from the self-attention layer.
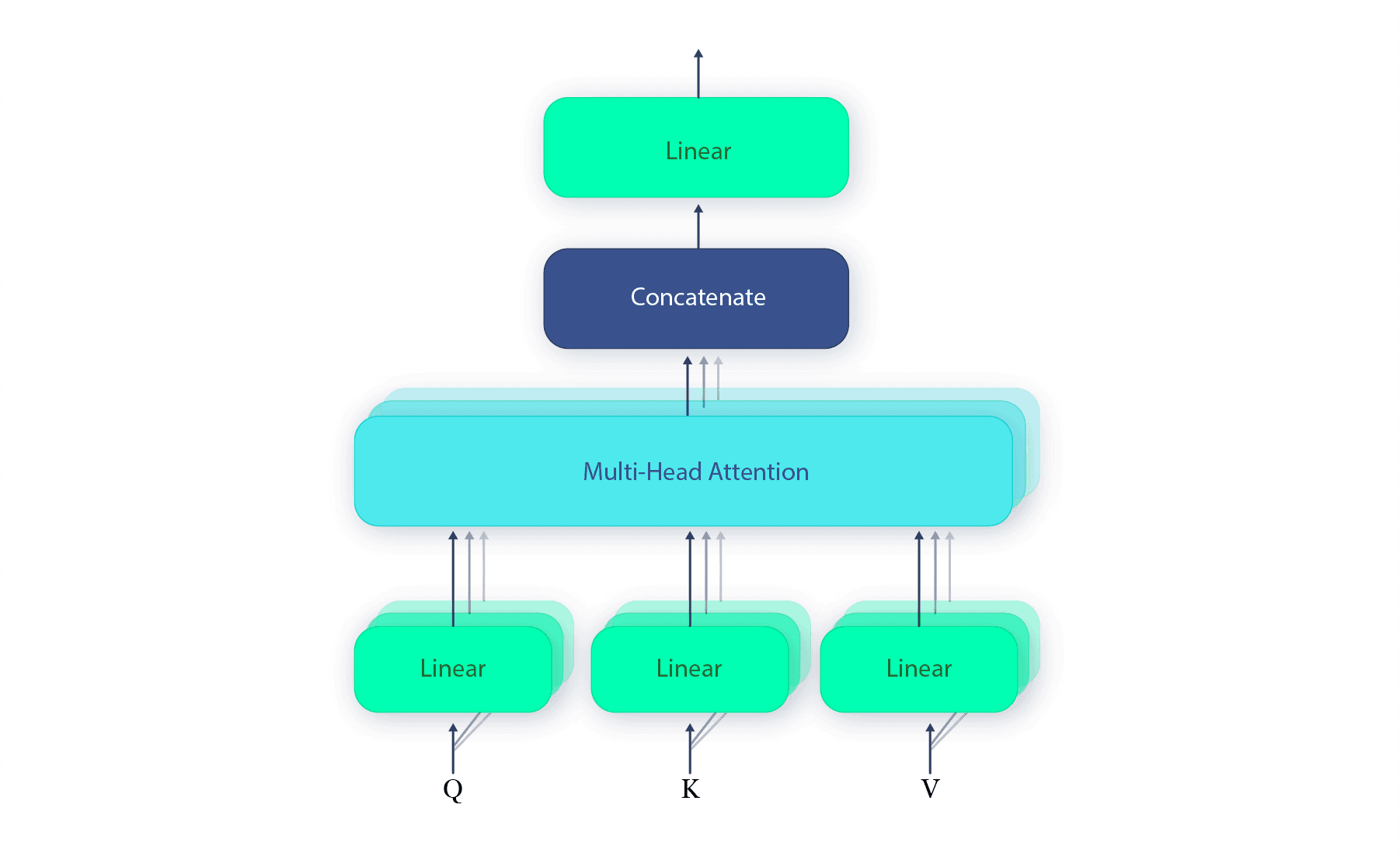
Luwei, Xiao & Hu, Xiaohui & Chen, Yinong & Xue, Yun & Chen, Bingliang & Gu, Donghong & Tang, Bixia. (2022). Multi-head self-attention based gated graph convolutional networks for aspect-based sentiment classification. Multimedia Tools and Applications. 81. 1-20. 10.1007/s11042-020-10107-0. Each sub-layer in the Encoder also employs a "residual connection" followed by "layer normalization." Residual connections help in training very deep networks by allowing gradients to flow more easily through the network, preventing vanishing gradient problems. Layer normalization helps stabilize the training process.
The output of the final Encoder layer is a set of contextualized embeddings for each token in the input sequence. These embeddings capture not only the semantic meaning of each word but also its relationship to every other word in the input, forming a rich representation of the input's meaning.
The Decoder: Generating Output Sequences
While the Encoder focuses on understanding the input, the Decoder's job is to generate an output sequence based on the Encoder's output and the previously generated tokens. While the Encoder is the “reader”, the Decoder becomes the "writer" of the Transformer.
Like the Encoder, the Decoder is also composed of a stack of identical layers. However, each Decoder layer has three sub-layers:
Masked Multi-Head Self-Attention: Similar to the Encoder's self-attention, but with a crucial modification: it's "masked." This masking ensures that during the generation process, the Decoder can only attend to previously generated words and the current word being predicted. It prevents the model from "cheating" by looking at future tokens in the output sequence. This is essential for autoregressive generation, where each word is predicted based on the preceding ones.
Encoder-Decoder Attention (Cross-Attention): This is where the Encoder and Decoder truly connect. This sub-layer performs attention over the output of the Encoder stack. It allows the Decoder to focus on relevant parts of the input sequence when generating the current output token. For example, in a translation task from English to Spanish, when the Decoder is generating a Spanish word, this mechanism helps it look back at the English sentence to find the most relevant English words for the translation.
Feed-Forward Network: Similar to the one in the Encoder, this network further processes the information after the attention mechanisms.
The output of the final Decoder layer passes through a linear layer and a softmax function. The softmax function converts the output into a probability distribution over the model's vocabulary, indicating the likelihood of each word being the next token in the sequence. The word with the highest probability is then selected as the predicted next token. This process is repeated autoregressively until a special end-of-sequence token is generated.
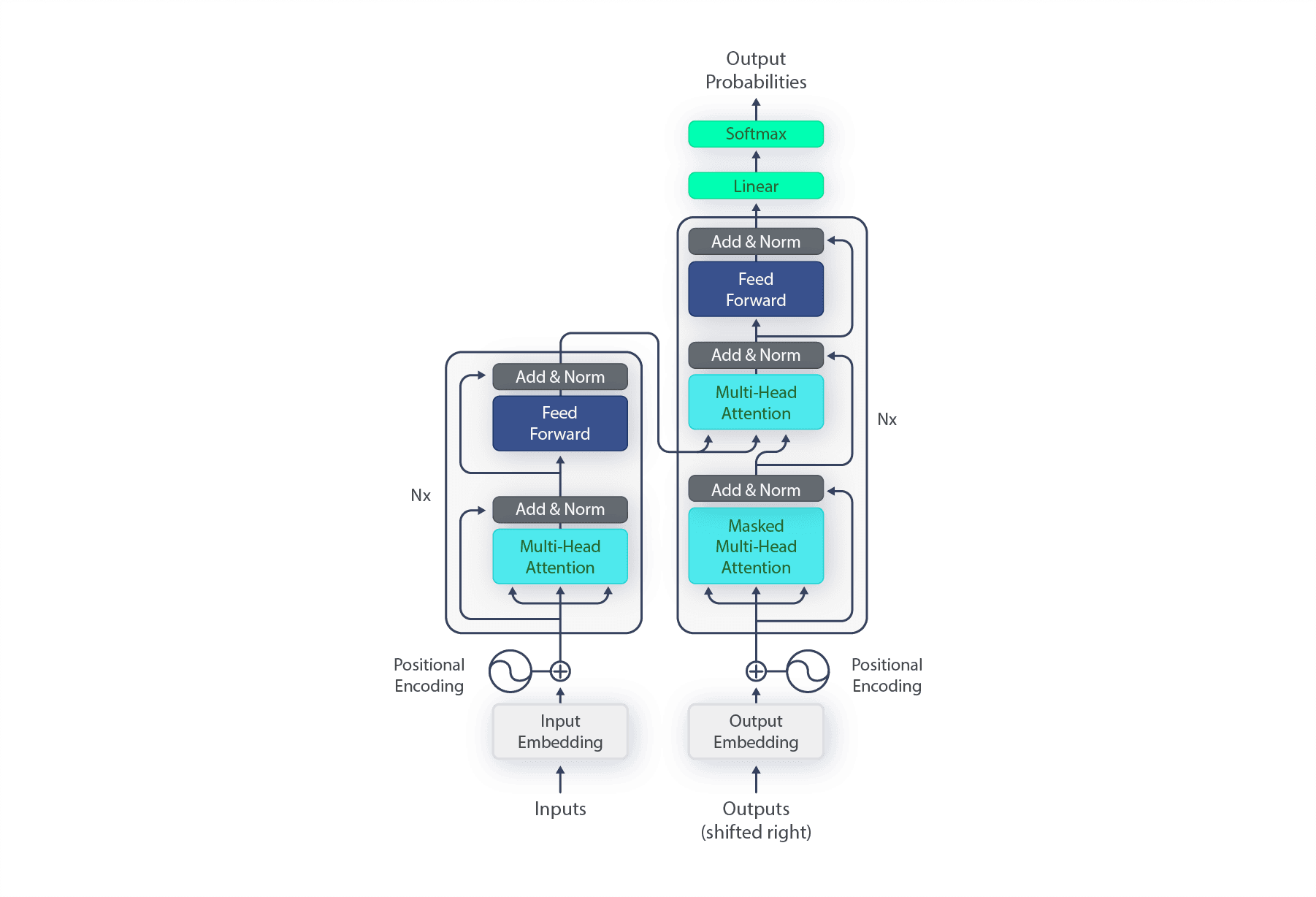
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30. You can also find it on arXiv: [1706.03762] Attention is All You Need - arXiv.
Variations in Transformer Architectures
While the full Encoder-Decoder Transformer is powerful for tasks like machine translation, many modern LLMs specialize in either encoding or decoding:
Encoder-Only Models (e.g., BERT, ALBERT, RoBERTa): These models primarily leverage the Encoder stack. They excel at tasks that require a deep understanding of the input text, such as: Sentence classification, Named Entity Recognition (NER), or Extractive question answering (finding the answer within the provided text). They are often used for "understanding" tasks rather than "generating" new text.
Decoder-Only Models (e.g., GPT, GPT-2, GPT-3, LLaMA): These models utilize only the Decoder stack (with the Encoder-Decoder attention mechanism often removed or adapted for self-attention on the input). They are pre-trained to predict the next token in a sequence. This makes them incredibly powerful for generative tasks: Text generation (writing articles, stories, emails), Chatbots and conversational AI, Code generation or Creative writing. In generative AI, these decoder-based models are prevalent, and the term LLM is often used interchangeably with "decoder-based models".
Encoder-Decoder Models (e.g., BART, T5, mBART): These models use both the Encoder and Decoder parts of the Transformer. They are ideal for sequence-to-sequence tasks where both understanding the input and generating a coherent output are crucial: Summarization, Machine translation, or Generative question answering.
Transformers expand the “abilities” of Large Language Models
The Transformer architecture has been instrumental in the rise of LLMs. Its ability to efficiently process vast amounts of text data and learn intricate language patterns has led to models that can:
Generate coherent and contextually relevant text: This is the basis for creative writing, content generation, and sophisticated chatbots.
Understand complex queries: Enabling better search engines, question-answering systems, and intelligent assistants.
Perform zero-shot and few-shot learning: LLMs, especially decoder-only models, can often perform new tasks without explicit training examples (zero-shot) or with just a few examples (few-shot), showcasing their remarkable generalization abilities.
Exhibit Chain-of-Thought (CoT) reasoning: For complex tasks, some LLMs can generate a sequence of intermediate reasoning steps, leading to more accurate and explainable answers.
As AI continues to advance, the Transformer's principles will remain central to the development of even more powerful and versatile language models.

SHare THIS POST:






